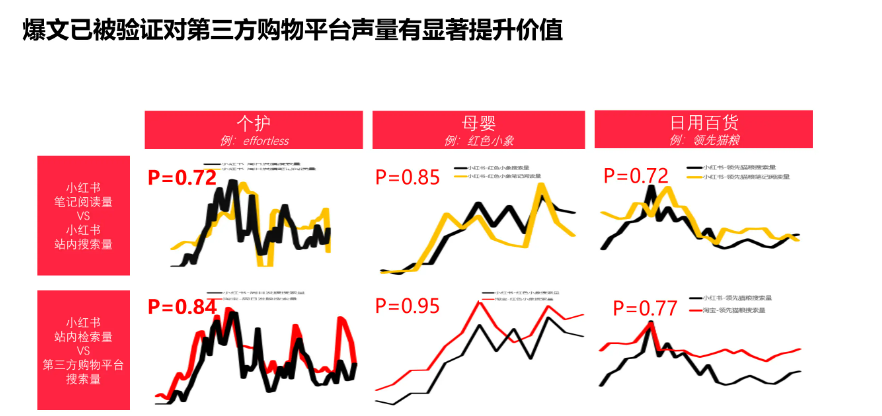
0.什么是lookalike?
一句话简单来说:广告主给定高质量的种子用户,系统需要自动发现类似的人群做投放。举个栗子,如果广告主提供的种子人群是持有某种信用卡的客户,那么相似人群就是在某些方面和种子人群相似。如果相似人员没有持有卡,那么他们也是有极大的可能去开卡的。
1.为什么要做lookalike?
目前存在的问题:人群标签组合无法覆盖全面,人群标签的挖掘成本太高了,无法支持人群分级定价等,lookalike可以简单、直接、漂亮地解决这些问题。
2.怎么做lookalike?
(1). 基于User-Feature的矩阵分解法
通过对user-feature矩阵分解,我们可以得到user-topic矩阵,如下图所示:

用户u和种子S的相似度定义如下(其中u是用户的的topic分布,Si是种子用户i的topic分布):

其中, 即为种子用户的平均topic分布。因此遍历全部人群,计算出每个用户与种子集合的相似度,取排序较高的作为扩展人群。
即为种子用户的平均topic分布。因此遍历全部人群,计算出每个用户与种子集合的相似度,取排序较高的作为扩展人群。
(2). 基于有监督的LR模型
我们将种子用户作为正例,随机用户进行下采样后作为负例,每一个种子单独训练一个LR模型。然后用这个模型对全部用户进行预测,我们认为预测值越大,和种子用户越相似。用户u和种子S的相似度定义如下(其中u是用户特征向量,w和b是LR模型的参数):

遍历全部人群,计算出所有用户的相似度,取top n即是扩展人群。在工程上实现的时候需要借助倒排索引,而随着广告主的增加,系统弊端逐渐暴露出来:倒排索引占用空间不断上涨,导致索引更新周期过长,每个用户身上的lookalike ID 也不得不按照相似度截断,而这种截断会加剧马太效应,对广告主扩展新用户是非常不利的。同时,离线模型训练和预测的机器也在不断增加。
(3). Online lookalike模型
在(2)的基础上,抛弃了原有的每个种子单独一个模型的思路,对所有的种子用户进行联合建模,具体网络结构如下:

在线召回广告的过程如下:首先从正排索引取到user embedding,接着用user embedding 向量和lookalike embedding 矩阵做乘法,得到 user 和每个广告的相似度,然后根据每个广告扩展倍数的阈值截断随机保留 n 个lookalike ID,将它们对应的广告召回。
3.小结
本文主要给出了广告智能定向中lookalike技术的定义、解决的问题以及具体的工程上的实现方式。
来源:计算广告